John Cutler's list of conflicting product management advice could apply to almost any business activity. How does it feel reading this? It's just a sample. More here.
"Be customer-obsessed."
Obsession leads to distortion.
"Teams need clear objectives!"
Having overly clear objectives can lead to tunnel vision and close doors prematurely.
"Think big. Start small."
There’s a lot of money in making a better mousetrap.

"You can’t improve what you don’t measure."
Not everything measurable matters, and not everything that matters is measurable.
"Focus on outcomes, not outputs."
You can’t make shots you don’t take.
"Lead by example!"
Don't encourage anyone to blindly copy you.
Yesterday, I asked someone building an open-sourced agent system (not a great idea, in my opinion) about whether there was any security risk in using his new package. His answer was not comforting, “Ya it executes the output of the model directly on your system, so there’s basically unlimited risk.”
[Unlimited risk...]
Maureen Dowd quoted a young idealistic Greg Brockman (an OpenAI cofounder) as saying back in the earliest day of OpenAI, “It’s not enough just to produce this technology and toss it over the fence and say, ‘OK, our job is done. Just let the world figure it out.’”
Gary Marcus, Marcus on AI Substack, "What Could Possibly Go Wrong With Sam Altman's Latest Ambitions, February 9th 2024
"Hire for culture fit!"
Over-emphasizing culture fit leads to homogeneity and stifles diversity.
"Be proactive!"
Avoid solving problems that don’t exist yet. Acting too early creates new problems.
Now consider sources of such advice all over the internet - not least LinkedIn, the source for that list. Consider prevalence of 'Top 5 ways to...' mainly because SEO likes numbers in headlines and listicles.
"Generative AI is still a solution in search of a problem"
Scott Rosenburg, Axios, April 24 2024
Consider how often you find a genuinely actionable or thought provoking search nugget and how often you get balanced product reviews and how to articles.
Now consider how all that content was broken down into small words or part words (tokens). Tokens and strings of tokens getting weaker or stronger scores (weights) for their relationships with one another. Relationships in terms of probability of being linked in a certain order.
Then, when the foundational multi-layered data nugget matrix is in place, we get Reinforcement Learning from Human Feedback (RLHF) or LLMs checking other LLM's homework. That is rating output based on a range of parameters like making sense, being accurate, being toxic etc. Work often outsourced.
That and other human driven activity tweaks weightings (thumbs up / down on chatbot responses, likes on LinkedIn AI articles to get 'Top Voice' badges, training on user interactions with chatbots where permitted).
Human or machine takes on best (or least bad) combinations of tokens, with a bunch of bolt on content moderation (don't swear, don't recommend illegal stuff, don't be too wordy, don't quote chunks of New York Times content verbatim).
Then we have domain specialist tuning (trying to improve likelihood of getting sums right and spelling strawberry) and linking databases of fixed references e.g. for coding, legal archives, or local business content, plus search results turned into tokens to keep responses current past the last training cut of date. All of which gets more or less reliably applied to threads, projects, canvases etc.

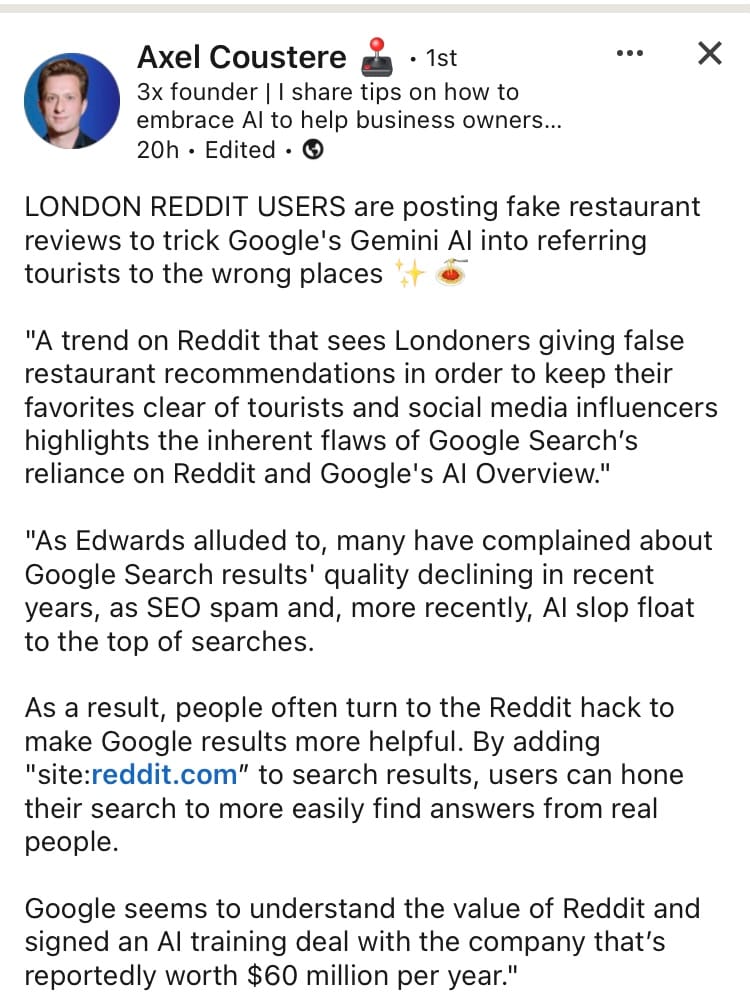
All that ignores the baseline 'flavour' and skew of content used for initial training. A bit of 4Chan here, a bit of X there, a big chunk of LinkedIn and Reddit, the full set of SEO-shaped management content (endless listicles and advertorials), the copied clickbait headlines and paragraphs only there to break up programatic ads.
If you asked an intern to summarise search page 1-6 for any given subject, what would you likely get? Received wisdom is not always a bad, but we react a certain way to folk who omit references and parrot opinions without critical thinking or domain experience. We put in quite a lot of work train folk and support them to refine output. That's ignoring constant immersion in a world that supports multi-sensory self-driven learning. How much roughly comparable effort goes into an AI training and checking output, for what kind of measurable benefit vs trade off?
When we try to change direction with content what might be an analogy? The amount a cold bath warms after adding a teacup of hot water? Or vice versa?
When issues accumulate or there is a big advance in materials or plumbing, then there is the massive job of retraining. Data isn't acquired from scratch and lessons learned are kept, including content moderation rules and other elements. Only a tiny handful of companies can afford to do that and service all the compute cost to run and support pre-existing and new models.
 Neal Weinberg
Neal Weinberg
Total Cost of generative AI Ownership is taking a while to surface. A typical TCO calculation stops far short of broader societal and environmental perspectives surfacing in reporting and variably represented in early AI regulation.
 Shaolei Ren
Shaolei RenWe are full of contradictions. What are we drawn to? What do we find enticing? Drama, promise, outrage, and simplicity vs the deathly complexity of plumbing. There is lots of graft to keep AI models ticking over and relatively free of toxic rubbish. All the messy jobs we take for granted. We don't like being mindful of that. We should therefore support folk who do sweat that small and cumulatively bigger stuff for us. Those who do things so we can worry less about AI and continue to wonder at experiences.
When trust breaks down with no easy way to check things and no bodies we recognise as empowered and able to check for us, it is very hard to rebuild that. This author and a lot of their peers work very hard to build trust back.